Welcome to our new blog post series about Landing Zones in Google. In this and the next blog posts, we will explain what is a landing zone, why you need it, describe the components of a landing zone and explain how to setup a landing zone.
What is a Landing Zone
A landing zone, as outlined by Google’s best practices, is a foundational element in constructing an organization’s Google Cloud Platform (GCP) infrastructure. It utilizes an Infrastructure-as-Code (IaC) approach to set up a GCP organization and manage the deployment of resources for various tenants. A tenant, in this context, refers to an independent entity—typically a team responsible for one or more applications—that consumes platform resources.
The rationale behind implementing a landing zone is to streamline and standardize the setup of an organization’s cloud environment. By following established best practices, a landing zone helps prevent the duplication of efforts among tenants, ensures the use of shared components, and enforces adherence to agreed-upon policies. All environment setups are done through approved IaC methods.
Why do we need a Landing Zone
The benefits of deploying a Landing Zone include:
A landing zone for the cloud is essential for several key reasons, especially for organizations looking to deploy and manage their cloud environments effectively and securely. Here are the primary reasons why a landing zone is needed:
1. Standardization: A landing zone provides a standardized approach to setting up and configuring cloud environments. This ensures that all deployments follow the same best practices, configurations, and security standards, leading to consistency across the organization’s cloud infrastructure. This also helps in reducing unnecessary complexity: Solutions are designed following a predefined methodology.
2. Security and Compliance: By establishing a set of security baselines and policies from the outset, a landing zone helps ensure that all cloud resources comply with the organization’s security requirements and regulatory standards. This preemptive approach to security greatly reduces the risk of vulnerabilities and breaches. As such, strengthening security posture is achieved by a common framework for security, access control, and patch management for improving security and compliance.
3. Efficiency and Scalability: With a landing zone, organizations can automate the provisioning of cloud resources, making it easier to scale up or down based on demand. This automation not only speeds up the deployment process but also reduces the likelihood of human error, contributing to a more reliable and efficient cloud environment.
4. Cost Management: Landing zones can help organizations avoid unnecessary costs by ensuring that resources are efficiently allocated and used. Through governance and standardized tagging, it becomes easier to track and manage cloud spending across different departments or projects.
5. Simplified Governance: A landing zone provides a framework for governance, allowing organizations to enforce policies, monitor compliance, and manage access control effectively. This simplifies the governance of cloud resources and helps maintain order as the cloud environment grows. For example, this helps inavoiding unmanaged project sprawl, which s achieved by deploying projects within a standard structure, using consistent naming conventions, and a uniform approach to labeling resources.
6. Faster Time to Market: By streamlining the setup process and enabling automation, landing zones reduce the time it takes to deploy new applications or services. This faster deployment capability can provide a competitive advantage by allowing organizations to bring solutions to market more quickly.
7. Resource Isolation: Landing zones can be designed to isolate resources between different environments (e.g., development, testing, production) or between different projects or tenants. This isolation enhances security and operational efficiency by preventing unintended interactions between resources.
8. Improving reliability: The use of automation, immutable infrastructure, and standardized monitoring, logging, and alerting mechanisms enhance system reliability.
9. Delegating resource management: Tenants are empowered to create and manage their resources within the landing zone framework, ensuring flexibility within a controlled environment.
In summary, landing zones are foundational to building a secure, efficient, and scalable cloud environment. They enable organizations to deploy cloud resources in a controlled, automated, and consistent manner, paving the way for innovation and growth while minimizing risks and costs.
What do you get?
After talking about the benefits of a Landing Zone, let’s talk about what you get with a Landing Zone.
1. Standardization and Efficiency: Landing Zones provide a repeatable, consistent approach for deploying cloud services using a standardized set of tools and Infrastructure-as-Code (IaC). This methodology prevents unnecessary duplication of effort and limits the proliferation of disparate products by employing curated and endorsed design blueprints as IaC.
2. IaC Capabilities:
A Landing Zone should be build by means of IaC. In order to have a repeatable set of components, the following elements can be provided:
Tenant Factory: Enables the creation of a top-level folder for a tenant along with an associated service account. In terms of Google, this is about configuring the Google organization.
Project Factory: Allows tenants to create their own projects using their service accounts, ensuring that resources are deployed exclusively via IaC and service accounts, except in sandbox projects where experimentation is allowed. With such a Project Factory, workload can later easily be onboarded with the Google Cloud.
CI/CD Toolchain: Facilitates automation and consistent deployment practices. We recommend using GitLab and GitLab CI, as already comes with support for Terraform.
3. Enforcement of Infrastructure Automation: To maintain consistency and agility, the use of infrastructure automation is enforced, preventing configuration drift and aligning with principles of automation and immutable infrastructure. This ensures that outcomes are predictable and that manual console-based configurations, which undermine consistency, are avoided. This involves not only using Terraform, but also have the “right DevOps workflows”, so that automation is done right.
4. Organizational Hierarchy and Policies:
Supports the creation of multiple isolated tenants within a platform, each with the autonomy to manage their own resources within defined boundaries.
Enforces a set of organization-wide policies aligned with best practices for security, such as preventing the creation of default networks, external IP addresses on compute instances, and mandating the use of OS Login for SSH access.
5. Predefined Network Topology:
Options for network topology include a shared VPC model or a hub-and-spoke pattern, promoting efficient resource allocation and connectivity among tenants while maintaining security through centralized control mechanisms like ingress and egress patterns.
Like other hyperscalers, Google already provides architectural guidelines and sample architectures for Landing Zones. For example, in the following, we can see a design from Google.
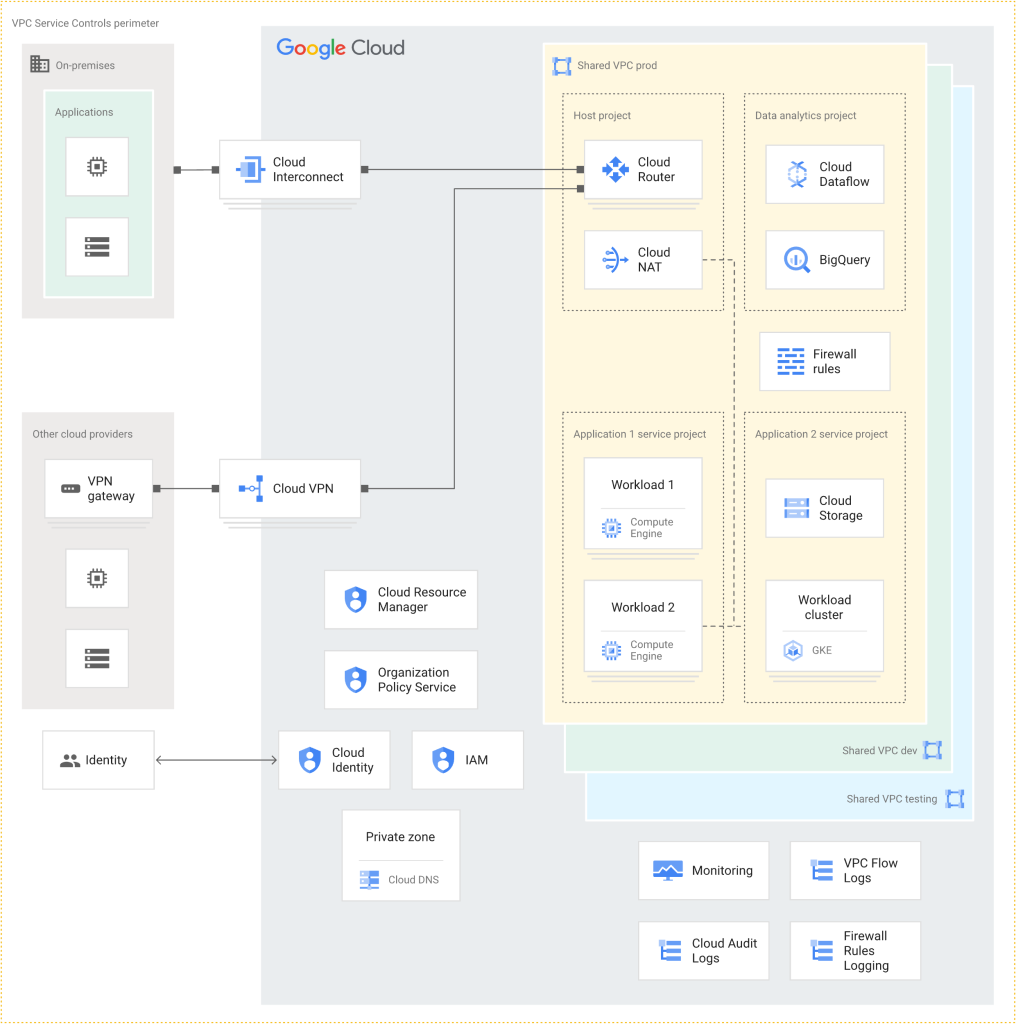
We at Soeldner Consult have a strategic partnership with CloudGems, for building Landing Zones in a very short time. Cloud Gems have their own design for a Landing Zone, which is very flexible and can be used in regulated environments as well as in traditional industries.